Kubernetes v1.36:Kubernetes PSI 指标升级到 GA
自 2018 年在 Linux 内核中首次实现以来, Pressure Stall Information(PSI)为用户提供了在资源饱和演变为停机之前识别它所需的高保真信号。 与传统的利用率指标不同,PSI 以 CPU、内存和 I/O 的时间百分比形式,清晰地展示了任务停滞和时间损失的情况。
随着 Kubernetes v1.36 的发布,生态系统中的用户现在拥有一个稳定、可靠的接口, 可在节点、Pod 和容器级别观察资源竞争情况。在本文中,我们将深入探讨证明其已准备好投入生产的改进和性能测试。
超越利用率:为什么选择 PSI?
仅监控 CPU 或内存使用情况可能会产生误导。一个节点可能报告 XX%(低于 100%)的 CPU 利用率, 而某些任务却因调度延迟而经历严重延迟。PSI 通过提供以下信息填补了这一空白:
- 累计总计:处于停滞状态的绝对时间。
- 移动平均值:10 秒、60 秒和 300 秒的窗口,允许运维人员区分瞬时峰值和持续的资源紧张。
证明稳定性:大规模性能测试
遥测功能升级时的一个常见担忧是收集和提供指标所需的资源开销。 为解决此问题,SIG Node 对各种机器类型上的高密度工作负载(80+ Pod)进行了广泛的性能验证。
我们的测试集中在两个主要场景,分别隔离 kubelet 和内核级别的收集影响:
- Kernel PSI ON / kubelet Feature OFF 对比 Kernel PSI ON / kubelet Feature ON(kubelet 开销)
- Kernel PSI OFF / kubelet Feature ON 对比 Kernel PSI ON / kubelet Feature ON(内核开销)
场景 1:kubelet 开销
首先,我们查看了 4 核机器上的 kubelet 使用情况(案例 1)。
对于这些机器,Linux 内核默认已经在两个集群上跟踪压力(psi=1),
但我们切换了 KubeletPSI 特性门控,以查看 kubelet 主动查询和暴露这些指标是否会影响资源使用。
图表中看到的同步突发在幅度和频率上几乎完全相同,证实了 kubelet 的收集逻辑非常轻量级,
可以无缝融入标准的内务处理周期。
该特性不会影响现有的资源使用,保持在正常的 0.1 核或节点总容量的 2.5% 以内,
因此对于生产规模的部署是安全的。
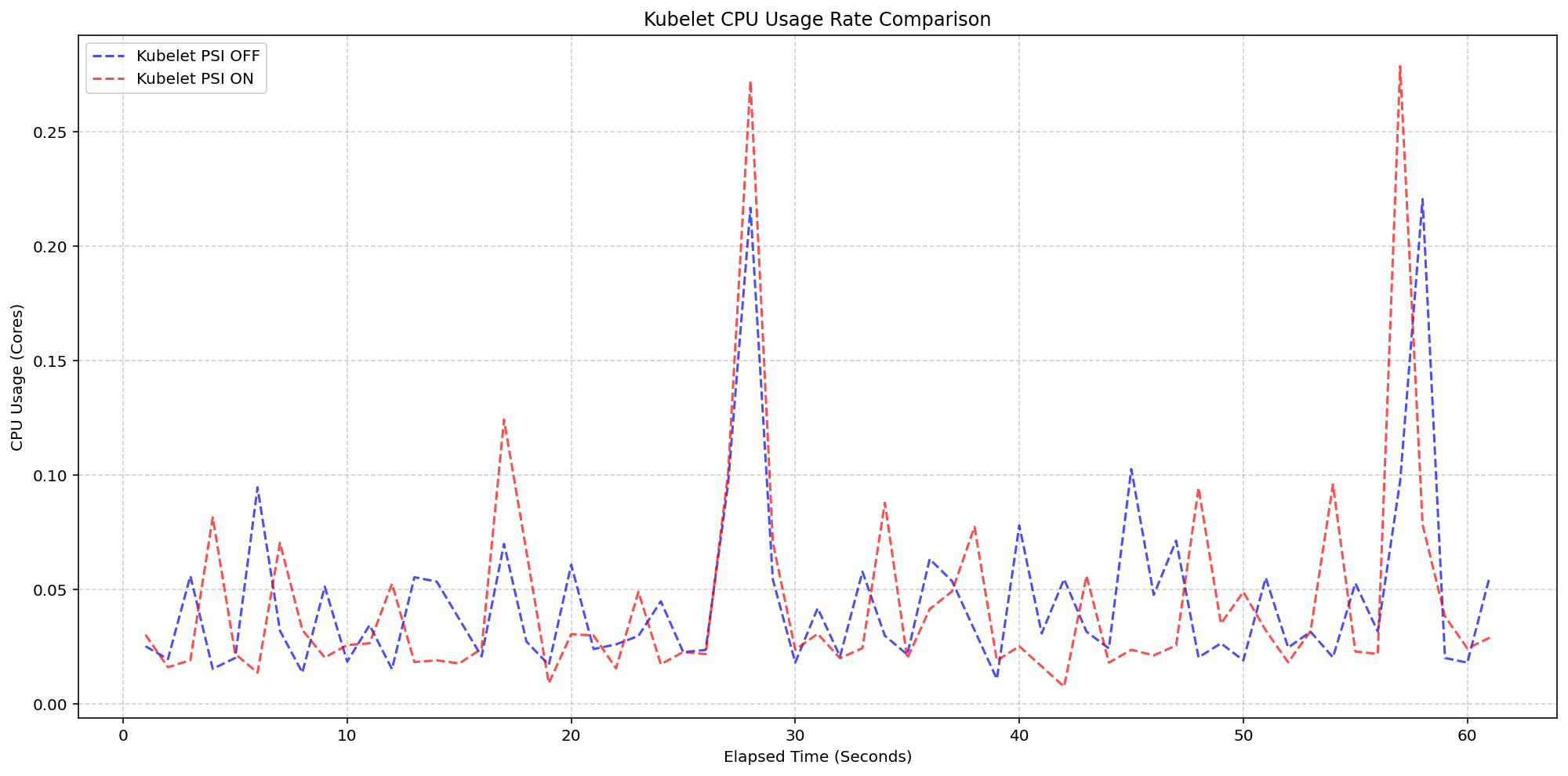
(案例 1)kubelet CPU 使用率对比
图 2:kubelet CPU 使用率对比。
接下来,我们在同一运行中评估了系统开销。 如下列图表所示,启用 Kubelet PSI(红色)的 System CPU 使用率曲线与禁用 kubelet PSI(蓝色)的集群遵循相同模式,比基线略有预期的增加。 这表明一旦操作系统跟踪 PSI(约 2.5 核), Kubernetes 读取这些 CGroup 指标的行为对性能的影响可以忽略不计。
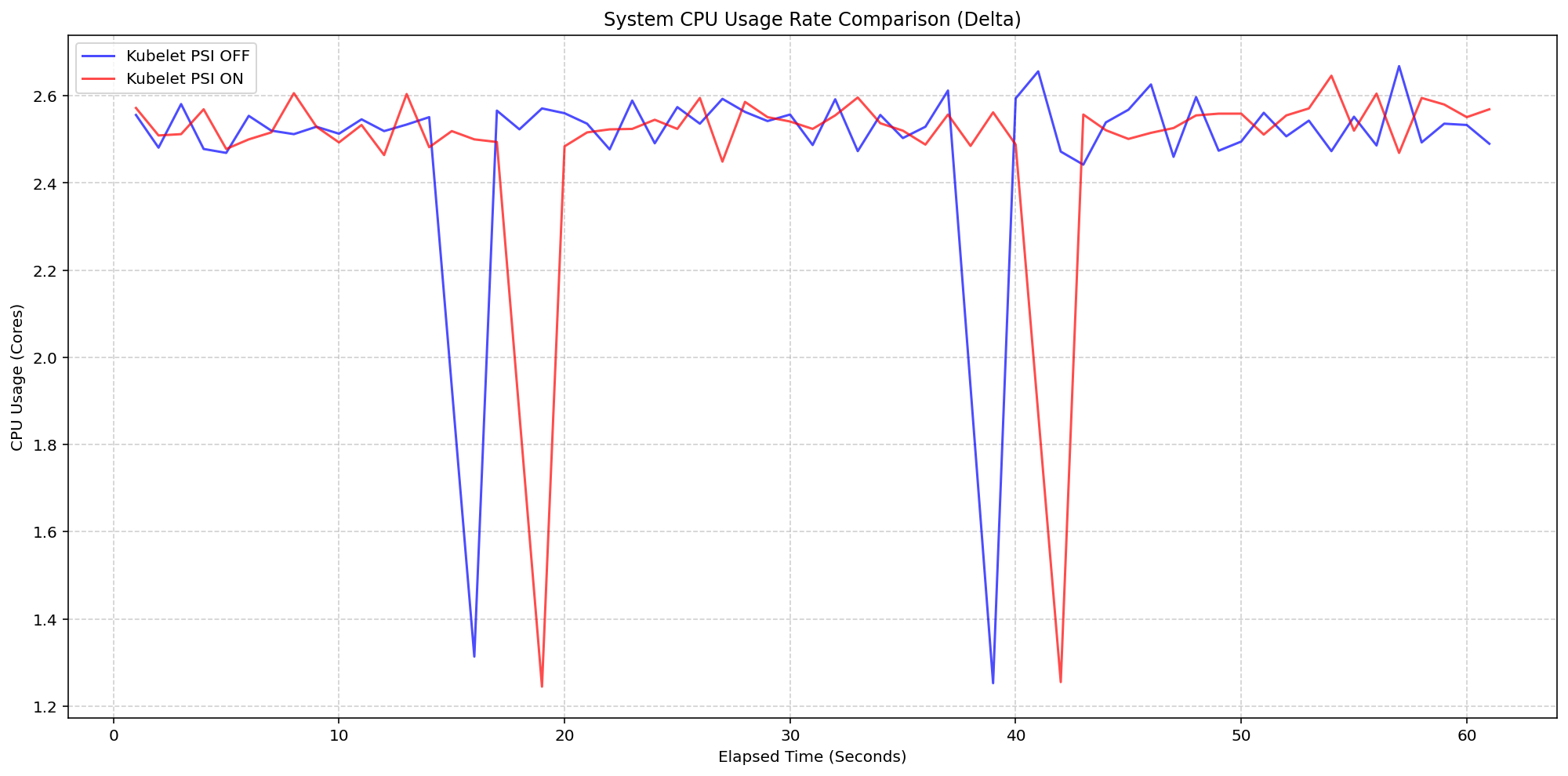
(案例 1)系统 CPU 使用率对比
图 1:节点系统 CPU 使用率对比。
场景 2:内核开销
换个角度,我们在 4 核机器上评估了在 Linux 内核上启用 PSI 的底层开销。
通过比较使用 psi=1(COS 默认值)启动的集群与使用 psi=0 的集群,
我们分离出了操作系统级簿记的确切成本。即使在 80 Pod 密度下的繁重 I/O 和 CPU 负载下,
启用内核和禁用内核的集群之间的 System CPU 差异始终保持在 0.037 核 到 0.125 核 之间,
即节点总容量的 0.925% - 3.125%。有一次峰值达到 0.225 核(即 5.6%),
但在几秒钟内就被控制下来。这证实了内核内部跟踪在负载下非常高效。
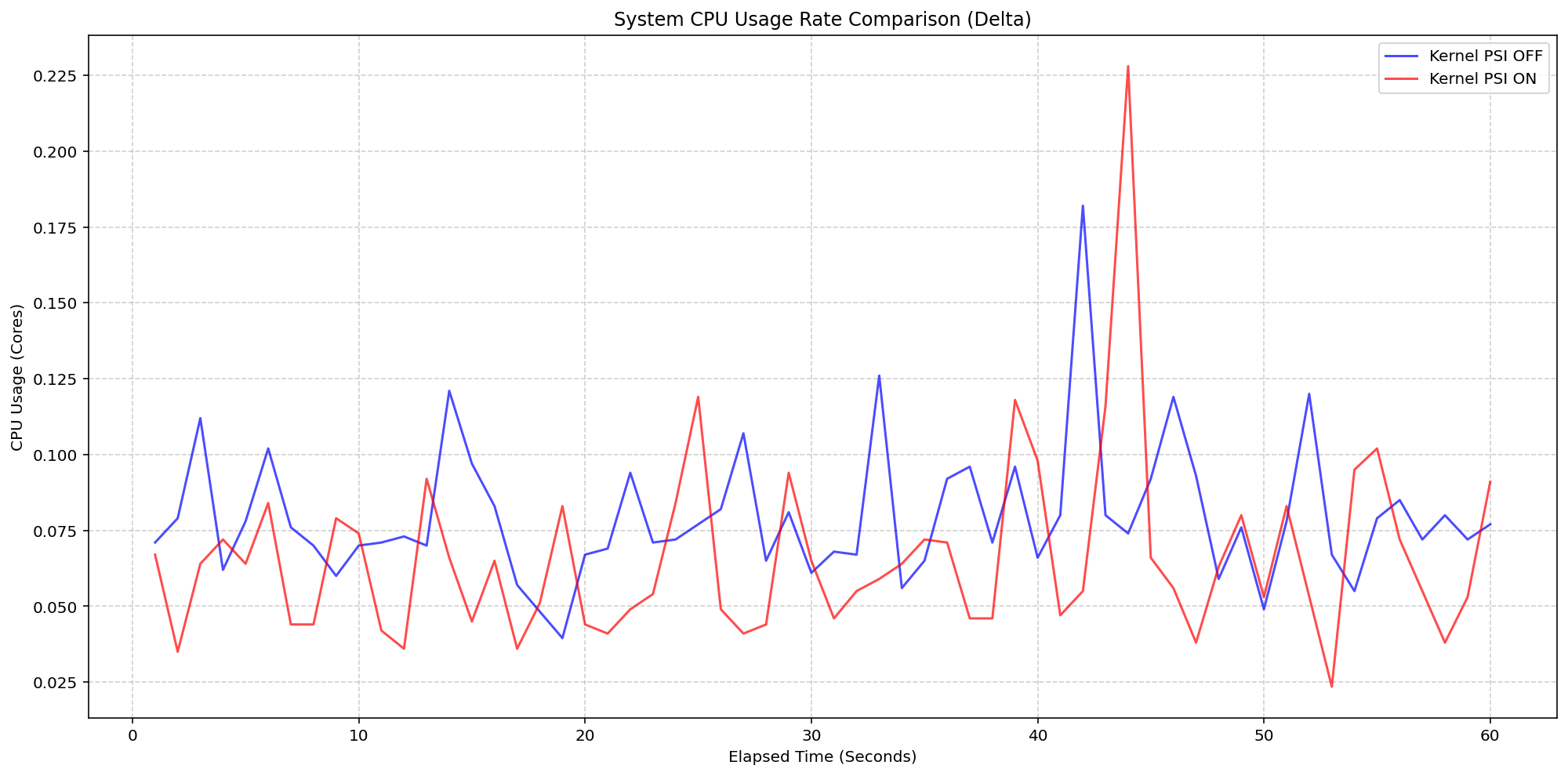
(案例 2)节点系统 CPU 使用率对比
图 3:节点系统 CPU 使用率对比。
图 4 放大了 kubelet 进程本身,它是这些指标的主要收集器。 结果表明,即使 kubelet 定期执行扫描以从 CGroup 层次结构聚合数据, 其 CPU 使用率仍然非常低,峰值可互换,且没有任何峰值超过 0.25 核 或总容量的 6.25% 超过一秒。
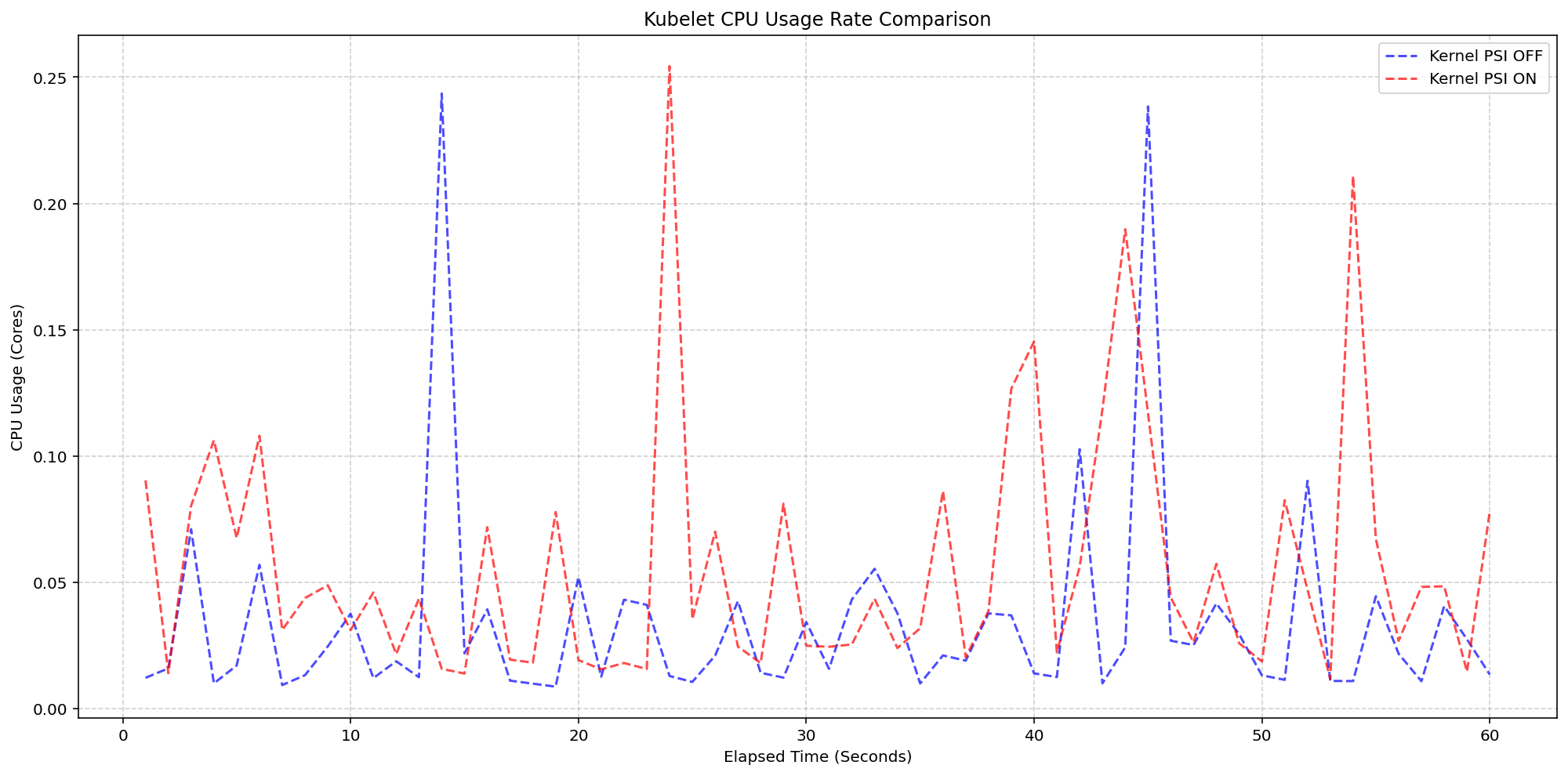
(案例 2)kubelet CPU 使用率对比
图 4:kubelet CPU 使用率对比。
Beta(1.34)到 Stable(1.36)之间的改进
- **GA 的智能指标发布:**我们改进了 kubelet 处理底层操作系统对 PSI 支持的方式。
以前,如果在 Kubernetes 中启用了该特性,但底层 Linux 内核不支持 PSI(
psi=0), kubelet 会发布误导性的零值指标。当这些指标被当作真实指标而不是缺失值读取时,可能会触发误报。 在 v1.36 中,kubelet 现在会在报告之前通过 CGroup 配置检测操作系统级别的 PSI 支持。 这确保了压力指标仅在节点实际支持时才被收集和发布,为监控和告警系统提供更清晰的数据。
入门指南
要在你的 Kubernetes 集群中使用 PSI 指标,你的节点必须满足以下要求:
- 确保你的节点运行 Linux 内核版本 4.20 或更高版本,并使用 CGroup v2。
- 确保在操作系统级别启用 PSI(你的内核必须使用
CONFIG_PSI=y编译,并且不得使用psi=0参数启动)。
从 v1.36 开始,Kubelet PSI 指标已普遍可用,你无需选择加入任何特性门控。
满足操作系统先决条件后,你可以开始使用兼容 Prometheus 的监控解决方案抓取 /metrics/cadvisor 端点,
或查询 Summary API 来收集和可视化新的 PSI 指标。
请注意,PSI 是 Linux 内核特性,因此这些指标在 Windows 节点上不可用。
你的集群可以包含 Linux 和 Windows 节点的混合,在 Windows 节点上,kubelet 将简单地省略 PSI 指标。
如果你的集群运行的是足够新的 Kubernetes 版本,并且你是特权节点管理员, 你还可以通过控制平面的 API 服务器代理到 kubelet 的 HTTP API, 以从 Summary API 查看实时压力数据。
**注意:**代理到 kubelet 是一项特权操作。授予访问权限存在安全风险, 因此在执行这些命令之前,请确保你拥有适当的管理权限。
CONTAINER_NAME="example-container"
kubectl get --raw "/api/v1/nodes/$(kubectl get nodes -o jsonpath='{.items[0].metadata.name}')/proxy/stats/summary" | jq '.pods[].containers[] | select(.name=="'"$CONTAINER_NAME"'") | {name, cpu: .cpu.psi, memory: .memory.psi, io: .io.psi}'
进一步阅读
如果你想深入了解这些指标是如何计算和暴露的,请查看以下资源:
- 官方内核文档
- Kubernetes 文档中的 Understanding PSI
- cAdvisor Metrics Implementation
致谢
PSI 指标的支持是通过 SIG Node 的协作努力开发的。特别感谢所有在该特性从 v1.33 的 Alpha、v1.34 的 Beta 到 v1.36 的 GA 整个过程中帮助设计、实现、测试、审查和文档化的贡献者。
要为此特性提供反馈,请加入 Kubernetes Node 特别兴趣小组, 参与公共 Slack 频道(#sig-node)上的讨论, 或在 GitHub 上提交 Issue。
反馈
如果你有反馈并想分享使用此特性的经验,请加入讨论:
- SIG Node 社区页面
- Kubernetes Slack 的 #sig-node 频道
- SIG Node 邮件列表
SIG Node 很想了解你在生产中使用此特性的经验!